BrowserRendering - 1 - 주소창에 구글을 치면 어떻게 될까?
해당 시리즈는 브라우저내에서 원하는 페이지를 화면에 띄울때 정말 여러 개의 과정이 존재하는데 그 과정들에 대해 공부한 내용을 정리하고 복습하기 위해 만든 페이지입니다.
전체적인 과정
- 도메인을 통해 JS, HTML, CSS 파일을 받음
- 받은 파일들을 이용해 화면에 띄움(브라우저 랜더링)
- 랜더링 이후에 액션, 이벤트에 따라 Reflow와 Repaint 과정이 발생한다. => 최적화 필요
넓게 보면 이 3가지의 과정인 것 같습니다.

물론, 이렇게 설명하면 이미 브라우저 랜더링을 알고 있는 사람 빼고는 ‘얘가 무슨 말을 하는거지??’라는 생각을 가질 것 같습니다.
그리해서, 이번 페이지에서는 1번. 도메인을 통해 파일들을 받아오는 과정에 대해 설명하고 다음 페이지에서 2번과정, 다다음 페이지에서 3번과정을 설명하는 느낌의 시리즈 물로 만들어 보고자 합니다.
아래부터, 과정에 따른 설명을 적어보도록 하겠습니다.
1. 주소창에 원하는 주소를 입력한다
2. IP 주소를 찾는다.
2번 과정을 넓은 개념으로 적어둔 이유는 이 과정 안에서 여러 가지 상황에 따른 경우가 존재해서 그렇습니다.
- DNS 레코드를 캐시를 통해 찾을 수 있는 경우
- IP를 찾기 위해 네임 서버까지 가서, 현재 입력한 주소를 통해 IP를 받는 경우
이렇게 두 가지 경우가 존재하는데요.
먼저, DNS, 네임서버 그리고 DNS 레코드에 대해 간략히 이해하고 가보자면…
- DNS(Domain Name System) 은 범국제적 단위로 웹사이트의 IP 주소와 도메인 주소를 이어주는 환경/시스템 입니다. 약간 자료구조의 Hash Map 느낌인데 우리가 친 주소(key)를 통해 IP(value)를 찾게 해준다고 볼 수 있습니다.
- 네임 서버는 이런 DNS를 운영하는 서버입니다.
- DNS 레코드는 DNS에서 받은 요청을 어떻게 처리할 것인지에 대한 정보라고 합니다.
일단, 첫번째 경우부터 한 번 살펴보겠습니다.
2.1. DNS 레코드를 캐시를 통해 찾을 수 있는 경우
이 경우는 저희가 이 사이트를 이미 방문한 전적이 있을 때 발생하는 경우입니다.
한 마디로, 이미 간 기록이 캐시 내에 존재하기 때문에 저희는 굳이 네임 서버까지 가서 IP를 찾고 다시 돌아오는 고생을 할 필요가 없기 때문에 네트워크 트래픽, 데이터 전송 시간이 개선될 수 있기 때문에 더 좋습니다.
먼저, 캐시에는 찾아보니 4가지 종류가 있었습니다. 아래는 과정이 저희가 원하는 정보를 찾는 과정이 기술되어 있습니다.
-
처음에는 브라우저 캐시를 확인합니다. 브라우저는 일정한 기간동안 저희가 갔던 장소를 DNS 레코드 저장소에다가 저장을 해놓습니다. 그렇기 때문에, 만약에 저희가 원하는 정보가 DNS 레코드 저장소에 있으면 여기서 DNS 쿼리를 통해 저희가 원하는 정보를 찾을 수 있습니다!
-
없다면 OS 캐시를 확인합니다. OS도 DNS 레코드 캐시를 유지관리 하는 기능이 있기 때문에 OS에 대한 시스템 호출을 통해 만약, DNS 레코드가 존재한다면 가져 올 수 있겠죠?
-
OS 캐시에도 없었다면 라우터 캐시를 향해 가야 합니다. 라우터가 자체 DNS 레코드 캐시를 유지 관리를 하기 때문에 여기에 있기 때문입니다.
-
라우터 캐시에도 없다?? 이러면 마지막으로 ISP 캐시를 보러 갑니다. ISP는 DNS 레코드 캐시를 포함하는 자체 네임 서버를 유지관리 하기 때문에 한번 찔러 봅니다.
- ?? : 캐시 다 뒤져봤는데 없는데요? 저 어떡하죠?
- A : 어떡하긴 그냥 네임 서버 가야지요 히히
2.2 네임 서버로 가는 경우
저희는 일단 캐시에서 IP를 찾지 못한 상황이구요. 이제 저희가 해야될 건 우리가 갈 웹사이트에 대한 올바른 IP 주소를 찾을 때까지 인터넷에서 여러 네임 서버를 검색하는 해야 됩니다.
이 과정에서, IP 주소를 찾거나, 못 찾았다는 오류 주소가 뜰 때까지 현재 네임 서버 => 다음 네임 서버 => 다다음 네임 서버… 이렇게 반복되기 때문에 이런 유형의 검색을 reculsive search(재귀 검색)이라고 합니다.
이 상황에서 총대를 맨건 ISP입니다. ISP는 네임 서버를 인터넷의 다른 네임 서버에 응답을 요청하여 저희가 원하는 주소를 찾는 것에 대해 책임을 지는데 이걸 DNS recursor 라고 부릅니다.
아래는 DNS recursor가 IP를 찾을 때까지의 과정을 그림으로 나타낸 것입니다.

현재 저희가 접하는 많은 웹 사이트 URL은 총 4가지 단계의 도메인이 포함되어 있습니다. 각각 단계에서 DNS lookup 프로세스 중에 쿼리되는 고유한 네임서버 또한 존재합니다.
저희가 보는 URL이 www.google.com이라고 예시로 들고 진행해보겠습니다.
- 먼저, Root domain으로 이동합니다.
- 도착하면 DNS recursor가 root 네임 서버에 연락을 겁니다.
- root 네임 서버는 Top-level domains에 .com 네임 서버로 redirect 합니다.
- .com 네임 서버는 google.com 네임 서버로 redirect 할 것이구요.
- google.com 네임 서버는 DNS 기록에서 www.google.com에 매칭되는 IP 주소를 찾고 DNS recursor로 보내줍니다.
이 모든 요청들은 보내는 요청의 내용과 DNS recursor의 IP 주소가 포함되어 있는 작은 데이터 패킷들을 통해 보내집니다.
이 패킷들은 원하는 DNS 레코드를 가진 네임 서버에 도달할 때 까지 클라이언트와 서버를 여러 번 오가구요.
패킷들이 움직이는 것은 routing table에 기반합니다. Routing table을 통해서 어떤 길로 가야 가장 빠른지 확인할 수 있고, 만약 패킷이 도중에 loss되면 request fail error가 발생하게 됩니다.
3. 브라우저가 서버의 TCP connection
자, 저희는 드디어 원하던 IP를 얻었습니다. 이제 그럼 저희가 원하는 HTML, CSS, js 파일들을 받기 위해 먼저 서버와 연결을 해야 될 것 같아요.
이 서버와의 연걸은 인터넷 프로토콜을 사용해서 진행되는데, 보통 웹 사이트의 HTTP 요청은 TCP/IP를 통해 이뤄집니다.
일단은, 이 TCP/IP의 3 way handshake라는 프로세스를 통해 연결이 되는데 TCP/IP에 대한 설명은 다른 페이지에 해 두도록 하겠습니다. => TCP/IP란 무엇일까? (페이지 제작 예정)
만약, 안 보고 오셨더라도 저희는 일단, TCP/IP 프로토콜을 통해 서버와 연결이 잘 됬다!를 저희는 알고 있기 때문에 문제는 없습니다.
4. 브라우저의 웹 서버를 향한 HTTP request
이제 진짜, 파일들을 받을 수 있습니다.
클라이언트 브라우저(저희)는 이제 GET 요청을 통해 서버에게 저희가 원하는 사이트의 웹 페이지를 구성하는 파일들을 요구합니다.
보통 GET이 사용되긴 하는데 비밀 자료가 포함된다거나, form을 제출하는 상황에서는 POST 요청을 사용할 수도 있습니다.
위의 GET, POST는 REST API에서 나온 용어입니다. 이 또한 정리해둔 페이지를 하단에 첨부해볼께요! => REST는 뭐고 REST API는 뭐지? ( 페이지 제작 예정)
쨋든, 저희가 이러한 요청을 하면 부가적인 정보들이 많이 들어옵니다.
- browser identification(User-Agent 헤더)
- 받아들일 요청의 종류(Accept 헤더)
- 추가적인 요청을 위해 TCP connection을 유지를 요청하는 connection 헤더
- 브라우저에서 얻은 쿠키 정보
- 기타 등등
 (만약, 이런 결과값을 눈으로 보고 싶다면 Postman, firebug과 같은 API 테스트 툴을 사용해보셔도 좋을 것 같습니다.)
(만약, 이런 결과값을 눈으로 보고 싶다면 Postman, firebug과 같은 API 테스트 툴을 사용해보셔도 좋을 것 같습니다.)
5. 서버가 request를 처리하고 response를 생성
서버는 웹서버를 가지고 있습니다(i.e. Apache, IIS…). 이들은 브라우저로부터 요청을 받고 request handler한테 요청을 전달해서 요청을 읽고 response를 생성하게 합니다.
Request handler란 ASP.NET, PHP, Ruby 등으로 작성된 프로그램을 의미합니다.
이 Request handler는 요청과 요청의 헤더, 쿠키를 읽어서 요청이 무엇인지 파악하고 필요하다면 서버에 정보를 업데이트 합니다.
그 다음에 response를 특정한 포맷으로(JSON, XML, HTML) 작성합니다.
6. 서버가 HTTP response를 보냄.
서버의 response에는 요청한 웹페이지, status code, compression type(Content-Encoding), 어떻게 페이지를 캐싱할지(Cache-Control), 설정할 쿠키가 있다면 쿠키, 개인정보 등이 포함됩니다.
postman을 사용해서 네이버에서 받은 HTTP response의 header 입니다.
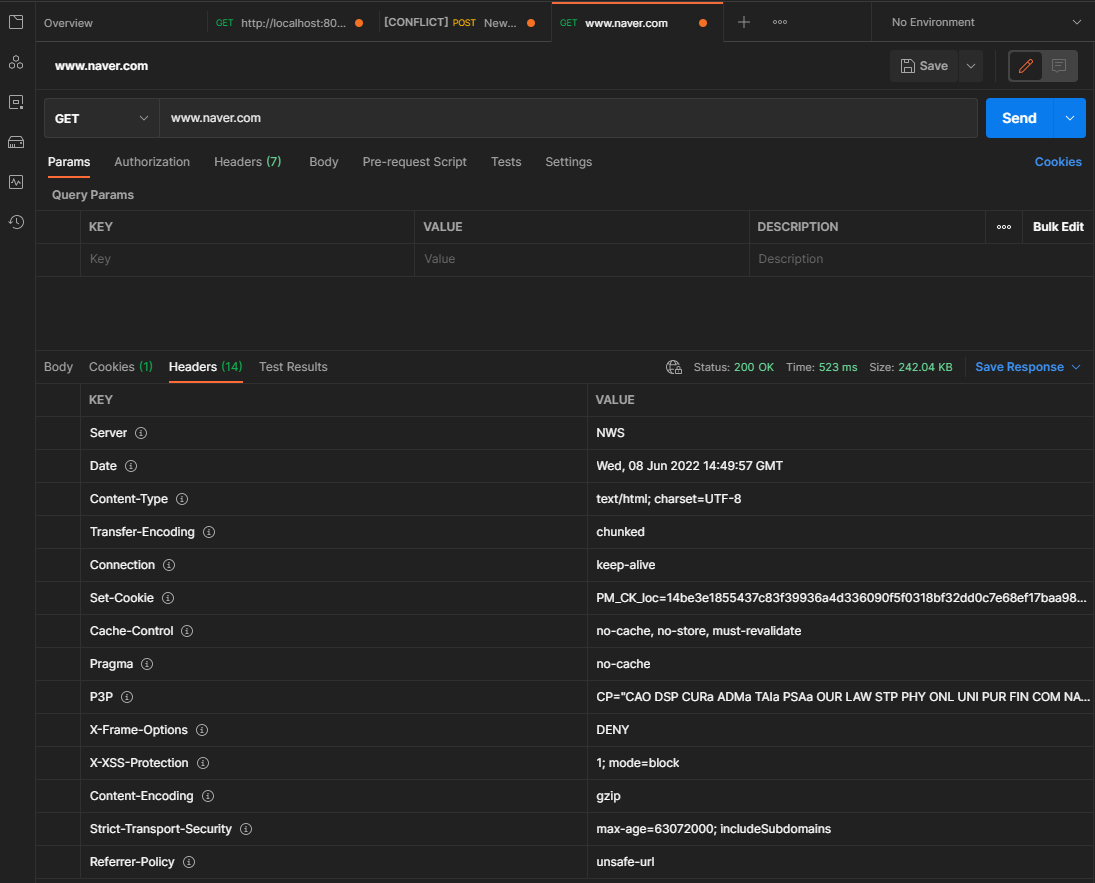
자세히 보시면 status : 200 OK라고 나와있는데 이게 Status code 입니다. Status code란 현재 response의 상태를 의미하고 총 5가지의 종류가 있습니다:
- 1xx은 정보만 담긴 메세지라는 것을 의미함.
- 2xx response가 성공적이라는 것을 의미함. => 보통 200인 것 같아요.
- 3xx 클라이언트를 다른 URL로 redirect함을 의미함.
- 4xx 클라이언트 측에서 에러가 발생했음을 의미함.
- 5xx 서버 측에서 에러가 발생했음읠 의미함.
8. Browser Rendering
이제, 드디어 저희가 다음 페이지에서 봐야할 브라우저 렌더링이 됩니다.
렌더링이 되고 나서, 또 서버랑 통신하면서 시간을 쓰는 것은 매우 아깝기 때문에 저희는 받아온 정적인 파일들을 Browser Elements들 중 자료 저장소 라는 곳에 저장해둡니다.
아마, 자료 저장소에 저희가 갈 사이트의 파일들이 존재한다면 통신은 안해도 되겠죠?
Browser Rendering 과정은 다음 포스트 글을 확인해주심 될 것 같아요. 오늘은 여기서 마치겠습니다.
감사합니다!
Reference
- https://devjin-blog.com/what-happen-browser-search/
- https://medium.com/@maneesha.wijesinghe1/what-happens-when-you-type-an-url-in-the-browser-and-press-enter-bb0aa2449c1a